There are many resources for network automation with Ansible. Most
of them only expose the first steps or limit themselves to a
narrow scope. They give no clue on how to expand from that. Real
network environments may be large, versatile, heterogeneous, and filled
with exceptions. The lack of real-world examples for Ansible
deployments, unlike Puppet and SaltStack, leads many teams to
build brittle and incomplete automation solutions.
We have released under an open-source license our attempt
to tackle this problem:
Jerikan, a tool to build configuration files from a single
source of truth and Jinja2 templates, along with its
integration into the GitLab CI system;
an Ansible playbook to deploy these configuration files on
network devices; and
the configuration data and the templates for our, now defunct,
datacenters in San Francisco and South Korea, covering many vendors
(Facebook Wedge 100, Dell S4048 and S6010, Juniper QFX 5110,
Juniper QFX 10002, Cisco ASR 9001, Cisco Catalyst 2960, Opengear
console servers, and Linux), and many functionalities
(provisioning, BGP-to-the-host routing, edge routing, out-of-band
network, DNS configuration, integration with NetBox and IRRs).
Here is a quick demo to configure a new peering:
This work is the collective effort of C dric Hasco t,
Jean-Christophe Legatte, Lo c Pailhas, S bastien Hurtel,
Tchadel Icard, and Vincent Bernat. We are the network team of
Blade, a French company operating Shadow, a cloud-computing
product. In May 2021, our company was bought by Octave Klaba and
the infrastructure is being transferred to OVHcloud, saving
Shadow as a product, but making our team redundant.
Our network was around 800 devices, spanning over 10 datacenters with
more than 2.5 Tbps of available egress bandwidth. The released
material is therefore a substantial example of managing a medium-scale
network using Ansible. We have left out the handling of our legacy
datacenters to make the final result more readable while keeping
enough material to not turn it into a trivial example.
Jerikan
The first component is Jerikan. As input, it takes a list of
devices, configuration data, templates, and validation scripts. It
generates a set of configuration files for each device. Ansible
could cover this task, but it has the following limitations:
Jerikan inputs and outputs
If you want to follow the examples, you only need to have Docker and
Docker Compose installed. Clone the repository and you
are ready!
Source of truth
We use YAML files, versioned with Git, as the single source of
truth instead of using a database, like NetBox, or a mix of a
database and text files. This provides many advantages:
anyone can use their preferred text editor;
the team prepares changes in branches;
the team reviews changes using merge requests;
the merge requests expose the changes to the generated configuration files;
rollback to a previous state is easy; and
it is fast.
The first file is devices.yaml. It contains the
device list. The second file is classifier.yaml.
It defines a scope for each device. A scope is a set of keys and
values. It is used in templates and to look up data associated with a
device.
The device name is matched against a list of regular expressions and
the scope is extended by the result of each match. For
to1-p1.sk1.blade-group.net, the following subset of
classifier.yaml defines its scope:
The third file is searchpaths.py. It describes
which directories to search for a variable. A Python function provides
a list of paths to look up in data/ for a given scope. Here
is a simplified version:2
Variables are scoped using a namespace that should be specified when
doing a lookup. We use the following ones:
system for accounts, DNS, syslog servers,
topology for ports, interfaces, IP addresses, subnets,
bgp for BGP configuration
build for templates and validation scripts
apps for application variables
When looking up for a variable in a given namespace, Jerikan looks
for a YAML file named after the namespace in each directory in the
search paths. For example, if we look up a variable for
to1-p1.sk1.blade-group.net in the bgp namespace, the following
YAML files are processed: host/sk1/to1-p1/bgp.yaml,
location/sk1/bgp.yaml, os/cumulus-dell-s4048/bgp.yaml,
os/cumulus/bgp.yaml, and common/bgp.yaml. The search stops at the
first match.
The schema.yaml file allows us to override this
behavior by asking to merge dictionaries and arrays across all
matching files. Here is an excerpt of this file for the topology
namespace:
The last feature of the source of truth is the ability to use Jinja2
templates for keys and values by prefixing them with ~ :
# In data/os/junos/system.yamlnetbox:manufacturer:Junipermodel:"~ model upper "# In data/groups/tor-bgp-compute/system.yamlnetbox:role:net_tor_gpu_switch
Looking up for netbox in the system namespace for
to1-p2.ussfo03.blade-group.net yields the following result:
# In groups/adm-gateway/topology.yamlinterface-rescue:address:"~ lookup('topology','addresses').rescue "up:-"~iprouteadddefaultvialookup('topology','addresses').rescue ipaddr('first_usable')tablerescue"-"~ipruleaddfromlookup('topology','addresses').rescue ipaddr('address')tablerescuepriority10"# In groups/adm-gateway-sk1/topology.yamlinterfaces:ens1f0:"~ lookup('topology','interface-rescue') "
This yields the following result:
$ ./run-jerikan lookup gateway1.sk1.blade-group.net topology interfaces
[ ]ens1f0: address: 121.78.242.10/29 up: - ip route add default via 121.78.242.9 table rescue - ip rule add from 121.78.242.10 table rescue priority 10
When putting data in the source of truth, we use the following rules:
Don t repeat yourself.
Put the data in the most specific place without breaking the first rule.
Use templates with parsimony, mostly to help with the previous rules.
Restrict the data model to what is needed for your use case.
The first rule is important. For example, when specifying IP addresses
for a point-to-point link, only specify one side and deduce the other
value in the templates. The last rule means you do not need to mimic a
BGP YANG model to specify BGP peers and policies:
Templates are using Jinja2. This is the same engine used in
Ansible. Jerikan ships some custom filters but also reuse some of
the useful filters from Ansible, notably
ipaddr. Here is an excerpt of
templates/junos/base.j2 to configure DNS
and NTP servers on Juniper devices:
system ntp %forntpinlookup("system","ntp")% server ntp; %endfor% name-server %fordnsinlookup("system","dns")% dns; %endfor%
devices() returns the list of devices matching a set of
conditions on the scope. For example, devices("location==ussfo03",
"groups==tor-bgp") returns the list of devices in San Francisco in
the tor-bgp group. You can also omit the operator if you want the
specified value to be equal to the one in the local scope. For
example, devices("location") returns devices in the current
location.
lookup() does a key lookup. It takes the namespace, the key, and
optionally, a device name. If not provided, the current device
is assumed.
scope() returns the scope of the provided device.
Here is how you would define iBGP sessions between edge devices in the
same location:
%forneighborindevices("location","groups==edge")ifneighbor!=device% %foraddressinlookup("topology","addresses",neighbor).loopbacktolist% protocols bgp group IPVaddressipv-EDGES-IBGP neighbor address description "IPvaddressipv: iBGP to neighbor"; %endfor% %endfor%
We also have a global key-value store to save information to be
reused in another template or device. This is quite useful to
automatically build DNS records. First, capture the IP address
inserted into a template with store() as a filter:
Templates are compiled locally with ./run-jerikan build. The
--limit argument restricts the devices to generate configuration
files for. Build is not done in parallel because a template may depend
on the data collected by another template. Currently, it takes 1
minute to compile around 3000 files spanning over 800 devices.
Output of Jerikan after building configuration files for six devices
When an error occurs, a detailed traceback is displayed, including the
template name, the line number and the value of all visible variables.
This is a major time-saver compared to Ansible!
templates/opengear/config.j2:15: in top-level template code
config.interfaces. interface .netmask adddress ipaddr("netmask")
continent = 'us'
device = 'con1-ag2.ussfo03.blade-group.net'
environment = 'prod'
host = 'con1-ag2.ussfo03'
infos = 'address': '172.30.24.19/21'
interface = 'wan'
location = 'ussfo03'
loop = <LoopContext 1/2>
member = '2'
model = 'cm7132-2-dac'
os = 'opengear'
shorthost = 'con1-ag2'
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = JerkianUndefined, query = 'netmask', version = False, alias = 'ipaddr'
[ ]
# Check if value is a list and parse each element
if isinstance(value, (list, tuple, types.GeneratorType)):
_ret = [ipaddr(element, str(query), version) for element in value]
return [item for item in _ret if item]
> elif not value or value is True:
E jinja2.exceptions.UndefinedError: 'dict object' has no attribute 'adddress'
We don t have general-purpose rules when writing templates. Like for
the source of truth, there is no need to create generic templates able
to produce any BGP configuration. There is a balance to be found
between readability and avoiding duplication. Templates can become
scary and complex: sometimes, it s better to write a filter or a
function in jerikan/jinja.py. Mastering
Jinja2 is a good investment. Take time to browse through our
templates as some of them show interesting features.
Checks
Optionally, each configuration file can be validated by a script in
the checks/ directory. Jerikan looks up the key checks
in the build namespace to know which checks to run:
In the above example, checks/junoser is executed if there is a
change to the generated config.txt file. It also outputs a
transformed version of the configuration file which is easier to
understand when using diff. Junoser checks a Junos configuration
file using Juniper s XML schema definition for Netconf.5 On
error, Jerikan displays:
jerikan/build.py:127: RuntimeError
-------------- Captured syntax check with Junoser call --------------
P: checks/junoser edge2.ussfo03.blade-group.net
C: /app/jerikan
O:
E: Invalid syntax: set system syslog archive size 10m files 10 word-readable
S: 1
Integration into GitLab CI
The next step is to compile the templates using a CI. As we are using
GitLab, Jerikan ships with a .gitlab-ci.yml
file. When we need to make a change, we create a dedicated branch and
a merge request. GitLab compiles the templates using the same
environment we use on our laptops and store them as an artifact.
Merge request to add a new port in USSFO03. The templates were compiled successfully but approval from another team member is still required to merge.
Before approving the merge request, another team member looks at the
changes in data and templates but also the differences for the
generated configuration files:
The change configures a port on the Juniper device, adds records to DNS, and updates NetBox with the new IP addresses (not shown).
Ansible
After Jerikan has built the configuration files, Ansible takes
over. It is also packaged as a Docker image to avoid the trouble to
maintain the right Python virtual environment and ensure everyone is
using the same versions.
InventoryJerikan has generated an inventory file. It contains all the managed
devices, the variables defined for each of them and the groups
converted to Ansible groups:
in-sync is a special group for devices which configuration should
match the golden configuration. Daily and unattended, Ansible should
be able to push configurations to this group. The mid-term goal is to
cover all devices.
none is a special device for tasks not related to a specific host.
This includes synchronizing NetBox, IRR objects, and the DNS,
updating the RPKI, and building the geofeed files.
Playbook
We use a single playbook for all devices. It is described in the
ansible/playbooks/site.yaml file.
Here is a shortened version:
A host executes only one of the play. For example, a Junos device
executes the blade.junos role. Once a play has been executed, the
device is added to the done group and the other plays are skipped.
The playbook can be executed with the configuration files generated by
the GitLab CI using the ./run-ansible-gitlab command. This is a
wrapper around Docker and the ansible-playbook command and it
accepts the same arguments. To deploy the configuration on the edge
devices for the SK1 datacenter in check mode, we use:
We avoid using collections from Ansible Galaxy, the exception
being collections to connect and interact with vendor devices, like
cisco.iosxr collection. The quality of Ansible
Galaxy collections is quite random and it is an additional
maintenance burden. It seems better to write roles tailored to our
needs. The collections we use are in
ci/ansible/ansible-galaxy.yaml. We use
Mitogen to get a 10 speedup on Ansible executions on Linux
hosts.
We also have a few playbooks for operational purpose: upgrading the OS
version, isolate an edge router, etc. We were also planning on how to
add operational checks in roles: are all the BGP sessions up? They
could have been used to validate a deployment and rollback if there is
an issue.
Currently, our playbooks are run from our laptops. To keep tabs, we
are using ARA. A weekly dry-run on devices in the in-sync group
also provides a dashboard on which devices we need to run Ansible
on.
Configuration data and templatesJerikan ships with pre-populated data and templates matching the
configuration of our USSFO03 and SK1 datacenters. They do not exist
anymore but, we promise, all this was used in production back in the
days!
The latest iteration of our network infrastructure for SK1, USSFO03, and future data centers. The production network is using BGPttH using a spine-leaf fabric. The out-of-band network is using a simple L2 design, using the spanning tree protocol, as well as a set of console servers.
Notably, you can find the configuration for:
our edge routers
Some are running on Junos, like edge2.ussfo03, the others on
IOS-XR, like edge1.sk1. The implemented functionalities are
similar in both cases and we could swap one for the other. It
includes the BGP configuration for transits, peerings, and IX as
well as the associated BGP policies. PeeringDB is queried to get
the maximum number of prefixes to accept for peerings. bgpq3 and a
containerized IRRd help to filter received routes. A firewall is
added to protect the routing engine. Both IPv4 and IPv6 are
configured.
our BGP-based fabric
BGP is used inside the datacenter8 and is extended on
bare-metal hosts. The configuration is automatically derived from
the device location and the port number.9 Top-of-the-rack
devices are using passive BGP sessions for ports towards servers.
They are also serving a provisioning network to let them boot using
DHCP and PXE. They also act as a DHCP server. The design is
multivendor. Some devices are running Cumulus Linux, like
to1-p1.ussfo03, while some others are running Junos, like
to1-p2.ussfo03.
our out-of-band fabric
We are using Cisco Catalyst 2960 switches to build an L2 out-of-band
network. To provide redundancy and saving a few bucks on wiring, we
build small loops and run the spanning-tree protocol. See
ob1-p1.ussfo03. It is redundantly connected to our gateway
servers. We also use OpenGear devices for console access. See
con1-n1.ussfo03
our administrative gateways
These Linux servers have multiple purposes: SSH jump boxes, rescue
connection, direct access to the out-of-band network, zero-touch
provisioning of network devices,10 Internet access for management
flows, centralization of the console servers using Conserver,
and API for autoconfiguration of BGP sessions for bare-metal
servers. They are the first servers installed in a new datacenter
and are used to provision everything else. Check both the generated
files and the associated Ansible tasks.
Ansible does not even provide a line number when there is an
error in a template. You may need to find the problem by
bisecting.
$ ansible --version
ansible 2.10.8[ ]$ cat test.j2
Hello name !$ ansible all -i localhost, \> --connection=local\> -m template \> -a "src=test.j2 dest=test.txt"localhost FAILED! => "changed": false, "msg": "AnsibleUndefinedVariable: 'name' is undefined"
You may recognize the same concepts as in Hiera, the
hierarchical key-value store from Puppet. At first, we were
using Jerakia, a similar independent store exposing an HTTP
REST interface. However, the lookup overhead is too large for our
use. Jerikan implements the same functionality within a Python
function.
The list of available filters is mangled inside
jerikan/jinja.py. This is a remain of the
fact we do not maintain Jerikan as a standalone software.
This is a bit confusing: we have a store() filter and a
store() function. With Jinja2, filters and functions live in
two different namespaces.
We are using a fork with some modifications to be able to
validate our configurations and exposing an HTTP service to
reduce the time spent on each configuration check.
There is a trend in network automation to automate a
configuration subset, for example by having a playbook to create a
new BGP session. We believe this is wrong: with time, your
configuration will get out-of-sync with its expected state,
notably hand-made changes will be left undetected.
We also have some datacenters using BGP EVPN VXLAN at
medium-scale using Juniper devices. As they are still in
production today, we didn t include this feature but we may
publish it in the future.
In retrospect, this may not be a good idea unless you are
pretty sure everything is uniform (number of switches for each
layer, number of ports). This was not our case. We now think it is
a better idea to assign a prefix to each device and write it in
the source of truth.
Non-linux based devices are upgraded and configured
unattended. Cumulus Linux devices are automatically upgraded on
install but the final configuration has to be pushed using
Ansible: we didn t want to duplicate the configuration process
using another tool.
Previously in George Orwell travel posts: Sutton Courtenay, Marrakesh, Hampstead, Paris, Southwold & The River Orwell.
Wallington is a small village in Hertfordshire, approximately fifty miles north of London and twenty-five miles from the outskirts of Cambridge. George Orwell lived at No. 2 Kits Lane, better known as 'The Stores', on a mostly-permanent basis from 1936 to 1940, but he would continue to journey up from London on occasional weekends until 1947.
His first reference to The Stores can be found in early 1936, where Orwell wrote from Lancashire during research for The Road to Wigan Pier to lament that he would very much like "to do some work again impossible, of course, in the [current] surroundings":
I am arranging to take a cottage at Wallington near Baldock in Herts, rather a pig in a poke because I have never seen it, but I am trusting the friends who have chosen it for me, and it is very cheap, only 7s. 6d. a week [ 20 in 2021].
For those not steeped in English colloquialisms, "a pig in a poke" is an item bought without seeing it in advance. In fact, one general insight that may be drawn from reading Orwell's extant correspondence is just how much he relied on a close network of friends, belying the lazy and hagiographical picture of an independent and solitary figure. (Still, even Orwell cultivated this image at times, such as in a patently autobiographical essay he wrote in 1946. But note the off-hand reference to varicose veins here, for they would shortly re-appear as a symbol of Winston's repressed humanity in Nineteen Eighty-Four.)
Nevertheless, the porcine reference in Orwell's idiom is particularly apt, given that he wrote the bulk of Animal Farm at The Stores his 1945 novella, of course, portraying a revolution betrayed by allegorical pigs. Orwell even drew inspiration for his 'fairy story' from Wallington itself, principally by naming the novel's farm 'Manor Farm', just as it is in the village. But the allusion to the purchase of goods is just as appropriate, as Orwell returned The Stores to its former status as the village shop, even going so far as to drill peepholes in a door to keep an Orwellian eye on the jars of sweets. (Unfortunately, we cannot complete a tidy circle of references, as whilst it is certainly Napoleon Animal Farm's substitute for Stalin who is quoted as describing Britain as "a nation of shopkeepers", it was actually the maraisardBertrand Bar re who first used the phrase).
"It isn't what you might call luxurious", he wrote in typical British understatement, but Orwell did warmly emote on his animals. He kept hens in Wallington (perhaps even inspiring the opening line of Animal Farm: "Mr Jones, of the Manor Farm, had locked the hen-houses for the night, but was too drunk to remember to shut the pop-holes.") and a photograph even survives of Orwell feeding his pet goat, Muriel. Orwell's goat was the eponymous inspiration for the white goat in Animal Farm, a decidedly under-analysed character who, to me, serves to represent an intelligentsia that is highly perceptive of the declining political climate but, seemingly content with merely observing it, does not offer any meaningful opposition. Muriel's aesthetic of resistance, particularly in her reporting on the changes made to the Seven Commandments of the farm, thus rehearses the well-meaning (yet functionally ineffective) affinity for 'fact checking' which proliferates today. But I digress.
There is a tendency to "read Orwell backwards", so I must point out that Orwell wrote several other works whilst at The Stores as well. This includes his Homage to Catalonia, his aforementioned The Road to Wigan Pier, not to mention countless indispensable reviews and essays as well. Indeed, another result of focusing exclusively on Orwell's last works is that we only encounter his ideas in their highly-refined forms, whilst in reality, it often took many years for concepts to fully mature we first see, for instance, the now-infamous idea of "2 + 2 = 5" in an essay written in 1939.
This is important to understand for two reasons. Although the ostentatiously austere Barnhill might have housed the physical labour of its writing, it is refreshing to reflect that the philosophical heavy-lifting of Nineteen Eighty-Four may have been performed in a relatively undistinguished North Hertfordshire village. But perhaps more importantly, it emphasises that Orwell was just a man, and that any of us is fully capable of equally significant insight, with to quote Christopher Hitchens "little except a battered typewriter and a certain resilience."
The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936.Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead.
Host to Kanchenjunga, the world s third-highest mountain peak and the endangered Red Panda, Sikkim is a state in northeastern India. Nestled between Nepal, Tibet (China), Bhutan and West Bengal (India), the state offers a smorgasbord of cultures and cuisines. That said, it s hardly surprising that the old spice route meanders through western Sikkim, connecting Lhasa with the ports of Bengal. Although the latter could also be attributed to cardamom (kali elaichi), a perennial herb native to Sikkim, which the state is the second-largest producer of, globally. Lastly, having been to and lived in India, all my life, I can confidently say Sikkim is one of the cleanest & safest regions in India, making it ideal for first-time backpackers.
Brief History
17th century: The Kingdom of Sikkim is founded by the Namgyal dynasty and ruled by Buddhist priest-kings known as the Chogyal.
1890: Sikkim becomes a princely state of British India.
1947: Sikkim continues its protectorate status with the Union of India, post-Indian-independence.
1973: Anti-royalist riots take place in front of the Chogyal's palace, by Nepalis seeking greater representation.
1975: Referendum leads to the deposition of the monarchy and Sikkim joins India as its 22nd state.
Languages
Official: English, Nepali, Sikkimese/Bhotia and Lepcha
Though Hindi and Nepali share the same script (Devanagari), they are not mutually intelligible. Yet, most people in Sikkim can understand and speak Hindi.
Ethnicity
Nepalis: Migrated in large numbers (from Nepal) and soon became the dominant community
Bhutias: People of Tibetan origin. Major inhabitants in Northern Sikkim.
Lepchas: Original inhabitants of Sikkim
Food
Tibetan/Nepali dishes (mostly consumed during winter)
Thukpa: Noodle soup, rich in spices and vegetables. Usually contains some form of meat. Common variations: Thenthuk and Gyathuk
Momos: Steamed or fried dumplings, usually with a meat filling.
Saadheko: Spicy marinated chicken salad.
Gundruk Soup: A soup made from Gundruk, a fermented leafy green vegetable.
Sinki : A fermented radish tap-root product, traditionally consumed as a base for soup and as a pickle. Eerily similar to Kimchi.
While pork and beef are pretty common, finding vegetarian dishes is equally easy.
Staple: Dal-Bhat with Subzi. Rice is a lot more common than wheat (rice) possibly due to greater carb content and proximity to West Bengal, India s largest producer of Rice.
Good places to eat in Gangtok
Hamro Bhansa Ghar, Nimtho (Nepali)
Taste of Tibet
Dragon Wok (Chinese & Japanese)
Buddhism in Sikkim
Bayul Demojong (Sikkim), is the most sacred Land in the Himalayas as per the belief of the Northern Buddhists and various religious texts.
Sikkim was blessed by Guru Padmasambhava, the great Buddhist saint who visited Sikkim in the 8th century and consecrated the land.
However, Buddhism is said to have reached Sikkim only in the 17th century with the arrival of three Tibetan monks viz. Rigdzin Goedki Demthruchen, Mon Kathok Sonam Gyaltshen & Rigdzin Legden Je at Yuksom. Together, they established a Buddhist monastery.
In 1642 they crowned Phuntsog Namgyal as the first monarch of Sikkim and gave him the title of Chogyal, or Dharma Raja.
The faith became popular through its royal patronage and soon many villages had their own monastery.
Today Sikkim has over 200 monasteries.
Major monasteries
Rumtek Monastery, 20Km from Gangtok
Lingdum/Ranka Monastery, 17Km from Gangtok
Phodong Monastery, 28Km from Gangtok
Ralang Monastery, 10Km from Ravangla
Tsuklakhang Monastery, Royal Palace, Gangtok
Enchey Monastery, Gangtok
Tashiding Monastery, 35Km from Ravangla
Reaching Sikkim
Gangtok, being the capital, is easiest to reach amongst other regions, by public transport and shared cabs.
About 20 minutes from Siliguri and 4 hours from Gangtok.
Reserved cabs cost about INR 3000. Shared cabs from INR 350.
By Road:
NH10 connects Siliguri to Gangtok
If you can t find buses plying to Gangtok directly, reach Siliguri and then take a cab to Gangtok.
Sikkim Nationalised Transport Div. also runs hourly buses between Siliguri and Gangtok and daily buses on other common routes. They re cheaper than shared cabs.
Wizzride also operates shared cabs between Siliguri/Bagdogra/NJP, Gangtok and Darjeeling. They cost about the same as shared cabs but pack in half as many people in luxury cars (Innova, Xylo, etc.) and are hence more comfortable.
The easiest & most economical way to explore North Sikkim is the 3D/2N package offered by shared-cab drivers.
This includes food, permits, cab rides and accommodation (1N in Lachen and 1N in Lachung)
The accommodation on both nights are at homestays with bare necessities, so keep your hopes low.
In the spirit of sustainable tourism, you ll be asked to discard single-use plastic bottles, so please carry a bottle that you can refill along the way.
Zero Point and Gurdongmer Lake are snow-capped throughout the year
3D/2N Shared-cab Package Itinerary
Day 1
Gangtok (10am) - Chungthang - Lachung (stay)
Day 2
Pre-lunch : Lachung (6am) - Yumthang Valley [12,139ft] - Zero Point - Lachung [15,300ft]
Post-lunch : Lachung - Chungthang - Lachen (stay)
Day 3
Pre-lunch : Lachen (5am) - Kala Patthar - Gurdongmer Lake [16,910ft] - Lachen
Post-lunch : Lachen - Chungthang - Gangtok (7pm)
This itinerary is idealistic and depends on the level of snowfall.
Some drivers might switch up Day 2 and 3 itineraries by visiting Lachen and then Lachung, depending upon the weather.
Areas beyond Lachen & Lachung are heavily militarized since the Indo-China border is only a few miles away.
East Sikkim
Zuluk and Silk Route
Time needed: 2D/1N
Zuluk [9,400ft] is a small hamlet with an excellent view of the eastern Himalayan range including the Kanchenjunga.
Was once a transit point to the historic Silk Route from Tibet (Lhasa) to India (West Bengal).
The drive from Gangtok to Zuluk takes at least four hours. Hence, it makes sense to spend the night at a homestay and space out your trip to Zuluk
Tsomgo Lake and Nathula
Time Needed : 1D
A Protected Area Permit is required to visit these places, due to their proximity to the Chinese border
Located on the Indo-Tibetan border crossing of the Old Silk Route, it is one of the three open trading posts between India and China.
Plays a key role in the Sino-Indian Trade and also serves as an official Border Personnel Meeting(BPM) Point.
May get cordoned off by the Indian Army in event of heavy snowfall or for other security reasons.
West Sikkim
Time needed: 3N/1N
Hostels at Pelling : Mochilerro Ostillo
Itinerary
Day 1: Gangtok - Ravangla - Pelling
Leave Gangtok early, for Ravangla through the Temi Tea Estate route.
Spend some time at the tea garden and then visit Buddha Park at Ravangla
Head to Pelling from Ravangla
Day 2: Pelling sightseeing
Hire a cab and visit Skywalk, Pemayangtse Monastery, Rabdentse Ruins, Kecheopalri Lake, Kanchenjunga Falls.
Day 3: Pelling - Gangtok/Siliguri
Wake up early to catch a glimpse of Kanchenjunga at the Pelling Helipad around sunrise
Head back to Gangtok on a shared-cab
You could take a bus/taxi back to Siliguri if Pelling is your last stop.
Darjeeling
In my opinion, Darjeeling is lovely for a two-day detour on your way back to Bagdogra/Siliguri and not any longer (unless you re a Bengali couple on a honeymoon)
Once a part of Sikkim, Darjeeling was ceded to the East India Company after a series of wars, with Sikkim briefly receiving a grant from EIC for gifting Darjeeling to the latter
Post-independence, Darjeeling was merged with the state of West Bengal.
Reach Darjeeling by noon and check in to your Hostel. I stayed at Hideout.
Spend the evening visiting either a monastery (or the Batasia Loop), Nehru Road and Mall Road.
Grab dinner at Glenary whilst listening to live music.
Day 2:
Wake up early to catch the sunrise and a glimpse of Kanchenjunga at Tiger Hill. Since Tiger Hill is 10km from Darjeeling and requires a permit, book your taxi in advance.
Alternatively, if you don t want to get up at 4am or shell out INR1500 on the cab to Tiger Hill, walk to the Kanchenjunga View Point down Mall Road
Next, queue up outside Keventers for breakfast with a view in a century-old cafe
Get a cab at Gandhi Road and visit a tea garden (Happy Valley is the closest) and the Ropeway. I was lucky to meet 6 other backpackers at my hostel and we ended up pooling the cab at INR 200 per person, with INR 1400 being on the expensive side, but you could bargain.
Get lunch, buy some tea at Golden Tips, pack your bags and hop on a shared-cab back to Siliguri. It took us about 4hrs to reach Siliguri, with an hour to spare before my train.
If you ve still got time on your hands, then check out the Peace Pagoda and the Darjeeling Himalayan Railway (Toy Train). At INR 1500, I found the latter to be too expensive and skipped it.
Tips and hacks
Download offline maps, especially when you re exploring Northern Sikkim.
Food and booze are the cheapest in Gangtok. Stash up before heading to other regions.
In rural areas and some cafes, you may get to try Rhododendron Wine, made from Rhododendron arboreum a.k.a Gurans. Its production is a little hush-hush since the flower is considered holy and is also the National Flower of Nepal.
If you don t want to invest in a new jacket, boots or a pair of gloves, you can always rent them at nominal rates from your hotel or little stores around tourist sites.
Check the weather of a region before heading there. Low visibility and precipitation can quite literally dampen your experience.
Keep your itinerary flexible to accommodate for rest and impromptu plans.
Shops and restaurants close by 8pm in Sikkim and Darjeeling. Plan for the same.
Carry
a couple of extra pairs of socks (woollen, if possible)
a pair of slippers to wear indoors
a reusable water bottle
an umbrella
a power bank
a couple of tablets of Diamox. Helps deal with altitude sickness
extra clothes and wet bags since you may not get a chance to wash/dry your clothes
a few passport size photographs
Shared-cab hacks
Intercity rides can be exhausting. If you can afford it, pay for an additional seat.
Call shotgun on the drives beyond Lachen and Lachung. The views are breathtaking.
Return cabs tend to be cheaper (WB cabs travelling from SK and vice-versa)
Cost
My median daily expenditure (back when I went to Sikkim in early March 2021) was INR 1350.
This includes stay (bunk bed), food, wine and transit (shared cabs)
In my defence, I splurged on food, wine and extra seats in shared cabs, but if you re on a budget, you could easily get by on INR 1 - 1.2k per day.
For a 9-day trip, I ended up shelling out nearly INR 15k, including 2AC trains to & from Kolkata
Note : Summer (March to May) and Autumn (October to December) are peak seasons, and thereby more expensive to travel around.
Souvenirs and things you should buy
Buddhist souvenirs :
Colourful Prayer Flags (great for tying on bikes or behind car windshields)
Miniature Prayer/Mani Wheels
Lucky Charms, Pendants and Key Chains
Cham Dance masks and robes
Singing Bowls
Common symbols: Om mani padme hum, Ashtamangala, Zodiac signs
I recently discovered SDF s PiDP-8.
You can access it over SSH and watch the blinkenlights over its twitch stream.
It runs TSS/8, a time-sharing operating system written in 1967 by Adrian van de Goor while a grad student here at CMU.
I ve been having fun tinkering with it, and I just wrote my first BASIC program1 since high school.
It plots the graph of some user-specified univariate function.
I don t claim that it s elegant or well-engineered, but it works!
10DEFFNC(X)=19*COS(X/2)20FORY=20TO-20STEP-130FORX=-25TO2440LETV=FNC(X)50GOSUB9060NEXTX70PRINT""80NEXTY85STOP90REM SUBROUTINE PRINTS AXES AND PLOT100IFX=0THEN150110IFY=0THEN150120REM X != 0 AND Y != 0 SO IN QUADRANT130GOSUB290140RETURN150GOSUB170160RETURN170REM SUBROUTINE PRINTS AXES (X = 0 OR Y = 0)180IFX+Y=0THEN230190IFX=0THEN250200IFY=0THEN270210PRINT"AXES INVARIANT VIOLATED"220STOP230PRINT"+";240GOTO280250PRINT"I";260GOTO280270PRINT"-";280RETURN290REM SUBROUTINE PRINTS FUNCTION GRAPH (X != 0 AND Y != 0)300IF0<=YTHEN350310REM Y < 0320IFV<=YTHEN410330REM Y < 0 AND Y < V SO OUTSIDE OF PLOT AREA340GOTO390350REM 0 <= Y360IFY<=VTHEN410370REM 0 <= Y AND V < Y SO OUTSIDE OF PLOT AREA380GOTO390390PRINT" ";400RETURN410PRINT"*";420RETURN430REM COPYRIGHT 2021 RYAN KAVANAGH RAK AT RAK.AC440END
It produces the following output:
I
I
* ** I **
* ** I **
** ** *I* ** *
** ** *I* ** *
** *** *I* *** *
** **** *I* **** *
** **** *I* **** *
** **** *I* **** *
** **** **I** **** *
*** **** **I** **** **
*** **** **I** **** **
*** **** **I** **** **
*** ***** **I** ***** **
*** ****** **I** ****** **
*** ****** **I** ****** **
*** ****** **I** ****** **
*** ****** **I** ****** **
*** ****** ***I*** ****** **
-------------------------+------------------------
****** ****** I ****** ******
****** ****** I ****** ******
***** ****** I ****** *****
***** ****** I ****** *****
***** ***** I ***** *****
***** ***** I ***** *****
***** ***** I ***** *****
***** **** I **** *****
***** **** I **** *****
**** **** I **** ****
**** **** I **** ****
*** **** I **** ***
*** *** I *** ***
*** *** I *** ***
*** *** I *** ***
** ** I ** **
** ** I ** **
* * I * *
I
I
Next up, I am going to try my hand at writing some FORTRAN or some FOCAL69.
If you like tinkering with old systems, then you should give the TSS/8 a try.
I switched from Jekyll to Hugo last week for a variety of reasons.
One thing that was missing was a port of the jekyll-static-comments plugin that I used to use.
I liked it because it saved readers from being tracked by Disqus or other comments solutions, and it required no javascript.
To comment, users would email me their comment following a template attached to the bottom of each post.
I then piped their email through a script to add it to the right post.
As an added benefit, I could delegate comment spam detection to my mail server.
I ve managed to reimplement this setup using Hugo.
For those who are interested in a similar setup, here is what you need to do.
Pages with comments
Instead of being single files, pages need to be leaf bundles.
For example, this means that your blog post must be located at /content/blog/2021-03-12-static-comments-in-hugo/index.md instead of /content/blog/2021-03-12-static-comments-in-hugo.md.
This lets you store the comments as page resources in the subdirectory /content/blog/2021-03-12-static-comments-in-hugo/comments/.
Partials
You should create a comments.html partial and include it in the layout for the pages which should get comments:
<divclass="post-comments"><pclass="comment-notice"><b>Comments</b>: To comment on this post,
send me an email following the template below. Your email address
will not be posted, unless you choose to include it in
the <spanstyle="font-family: monospace;">link:</span> field.</p><preclass="comment-notice">
To: Your Name <your.email<span>@</span>example.org>
Subject: [blog-comment] .Page.RelPermalink
post_id: .Page.RelPermalink
author: [How should you be identified? Usually your name or "Anonymous"]
link: [optional link to your website]
Your comments here. Markdown syntax accepted.</pre>
$scratch := newScratch
$scratch.Set "comments" (.Resources.Match "comments/*yml")
if eq 1 (len ($scratch.Get "comments"))
<h2>1 Comment</h2>
else
<h2> len ($scratch.Get "comments") Comments</h2>
end
range ($scratch.Get "comments")
<divclass="post-comment % cycle 'odd', 'even' % ">
$comment := (.Content transform.Unmarshal)
<spanclass="post-meta">
- $comment.date dateFormat "Jan 2, 2006 at 15:04" -
</span><h3class="comment-header">
if $comment.link
<ahref=" $comment.link "> $comment.author </a>
else
$comment.author
end
<br/></h3>
$comment.comment markdownify
</div>
end
</div>
Comments
To associate comments received by email to posts, I pipe them from mutt (using the keybinding) to the following (admittedly janky) shell script.
It takes the comment, reformats it appropriately, and puts it in the post s comments subdirectory.
Note that it determines which filename to use based on the email s contents, so make sure to check that the email doesn t contain anything nefarious before you pipe it into the script!
#!/bin/sh
# Copyright (C) 2016-2021 Ryan Kavanagh <rak@rak.ac># Distributed under the ISC licenseBLOG_BASE="/media/t/work/blog"MESSAGE=$(cat)EMAIL=$(echo"$ MESSAGE" grep "From:" sed -e 's/From[^<]*<\?\([^>]*\)>\?.*/\1/g;s/@/-at-/g')DATE=$(echo"$ MESSAGE" grep "Date:" sed -e 's/Date:\s*//g' xargs -0 date -Iseconds -u -d)POST_ID=$(echo"$ MESSAGE" grep "post_id:" sed -e 's/post_id: //g')COMMENTS_DIR="$ BLOG_BASE/content/$ POST_ID/comments/"COMMENT_FILE="$ COMMENTS_DIR/$ DATE_$ EMAIL.yml"# Strip out the email headers and whitespace until the start of the commentCOMMENT_WHOLE=$(echo"$ MESSAGE" sed -e '/^\s*$/,$!d;/^[^\s]/,$!d')# Indent everything after the comment headerCOMMENT_INDENTED=$(echo"$ COMMENT_WHOLE" sed -e '/^\s*$/,$ s/.*/ &/g ')# And add the comment headerCOMMENT_PREFIXED=$(echo"$ COMMENT_INDENTED" sed -e '0,/^\s*$/ s/^\s*$/comment: / ')[ -d "$ COMMENTS_DIR"] mkdir -p "$ COMMENTS_DIR"echo"Saving the comment to $ COMMENT_FILE"echo"date: $ DATE" tee "$ COMMENT_FILE"echo"$ COMMENT_PREFIXED" tee -a "$ COMMENT_FILE"
For example, the following comment in an email body:
post_id: /blog/2021-03-12-static-comments-in-hugo/
author: Ryan Kavanagh
link: https://rak.ac/
Dear self,
Here is a test comment for your blog post.
It supports *markdown* **syntax** and stuff .
Best,
Yourself
results in a file content/blog/2021-03-12-static-comments-in-hugo/comments/2021-03-12T18:47:25+00:00_rak-at-example.org.yml containing:
date:2021-03-12T18:47:25+00:00post_id:/blog/2021-03-12-static-comments-in-hugo/author:Ryan Kavanaghlink:https://rak.ac/comment: Dear self,
Here is a test comment for your blog post.
It supports *markdown* **syntax** and stuff .
Best,
Yourself
You can see the rendered output at the bottom of this page.
I have neglected the Valutakrambod library for a while, but decided
this weekend to give it a face lift. I fixed a few minor glitches in
several of the service drivers, where the API had changed since I last
looked at the code. I also added support for fetching the order book
from the newcomer Norwegian Bitcoin Exchange.
I alsod decided to migrate the project from github to gitlab in the
process. If you want a python library for talking to various currency
exchanges, check out
code for
valutakrambod.
This is what the output from 'bin/btc-rates-curses -c'
looked like a few minutes ago:
Name Pair Bid Ask Spread Ftcd Age Freq
Bitfinex BTCEUR 39229.0000 39246.0000 0.0% 44 44 nan
Bitmynt BTCEUR 39071.0000 41048.9000 4.8% 43 74 nan
Bitpay BTCEUR 39326.7000 nan nan% 39 nan nan
Bitstamp BTCEUR 39398.7900 39417.3200 0.0% 0 0 1
Bl3p BTCEUR 39158.7800 39581.9000 1.1% 0 nan 3
Coinbase BTCEUR 39197.3100 39621.9300 1.1% 38 nan nan
Kraken+BTCEUR 39432.9000 39433.0000 0.0% 0 0 0
Paymium BTCEUR 39437.2100 39499.9300 0.2% 0 2264 nan
Bitmynt BTCNOK 409750.9600 420516.8500 2.6% 43 74 nan
Bitpay BTCNOK 410332.4000 nan nan% 39 nan nan
Coinbase BTCNOK 408675.7300 412813.7900 1.0% 38 nan nan
MiraiEx BTCNOK 412174.1800 418396.1500 1.5% 34 nan nan
NBX BTCNOK 405835.9000 408921.4300 0.8% 33 nan nan
Bitfinex BTCUSD 47341.0000 47355.0000 0.0% 44 53 nan
Bitpay BTCUSD 47388.5100 nan nan% 39 nan nan
Coinbase BTCUSD 47153.6500 47651.3700 1.0% 37 nan nan
Gemini BTCUSD 47416.0900 47439.0500 0.0% 36 336 nan
Hitbtc BTCUSD 47429.9900 47386.7400 -0.1% 0 0 0
Kraken+BTCUSD 47401.7000 47401.8000 0.0% 0 0 0
Exchangerates EURNOK 10.4012 10.4012 0.0% 38 76236 nan
Norgesbank EURNOK 10.4012 10.4012 0.0% 31 76236 nan
Bitstamp EURUSD 1.2030 1.2045 0.1% 2 2 1
Exchangerates EURUSD 1.2121 1.2121 0.0% 38 76236 nan
Norgesbank USDNOK 8.5811 8.5811 0.0% 31 76236 nan
Yes, I notice the negative spread on Hitbtc. Either I fail to
understand their Websocket API or they are sending bogus data. I've
seen the same with Kraken, and suspect there is something wrong with
the data they send.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
Here s my (sixteenth) monthly update about the activities I ve done in the F/L/OSS world.
Debian
This was my 25th month of contributing to Debian.
I became a DM in late March 2019 and a DD on Christmas 19! \o/
This month was bat-shit crazy. Why? We ll come to it later, probably 15th of this month?
Anyway, besides being crazy, hectic, adventerous, and the first of 2021, this month I was super-insanely busy. With what? Hm, more about this later this month! ^_^
However, I still did some Debian stuff here and there. Here are the following things I worked on:
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my sixteenth month as a Debian LTS and seventh month as a Debian ELTS paid contributor.
I was assigned 26.00 hours for LTS and 36.75 hours for ELTS and worked on the following things:
(however, I worked extra for 9 hours for LTS and 9 hours for ELTS this month, which I intend to balance from the next month!)
LTS CVE Fixes and Announcements:
Issued DLA 2518-1, fixing CVE-2020-35492, for cairo.
For Debian 9 Stretch, these problems have been fixed in version 1.14.8-1+deb9u1.
Prepared DSA 4831-1, fixing CVE-2020-26298, for ruby-redcarpet.
For Debian 10 Buster, these problems have been fixed in version 3.4.0-4+deb10u1. The announcement was released by the Security Team.
This January, on 23rd and 24th, we had Mini DebConf India 2021 online.
I had a talk as well, titled, Why Point Releases are important and how you can help
prepare them?".
It was a fun and a very short talk, where I just list out the reasons and ways to help in
the preparation of point releases . I did some experimentation with this talk, figuring
out what works for the audience and what doesn t and where can I improve for the next time
I talk about this topic! \o/
You can listen to the talk here
and let me know if you have any feedback!
Anyway, the conference lasted for 2 days and I also did some volunteering (talk director,
talk miester) in Hindi and English, both! It was all so fun and new. Anyway, here s the picture we took:
In another exciting news, I got my first CVE assigned!!! \o/
No, it is not something that I found, it was discovered by Tavis Ormandy. I just assigned
this a CVE ID, CVE-2021-3181.
This is my first, so I am very excited about this! ^_^
Besides, there s something more that is in the pipelines. Can t talk about it now, shh. But
hopefully very sooooooon!
Other $things! \o/
This month was tiresome, with most of the time being spent on the Debian stuff, I did
very little work outside it, really. The issues and patches that I sent are:
Issue #700 for redcarpet, asking for a reproducer for CVE-2020-26298 and some additional patch related queries.
Issue #7 for in-parallel, asking them to not use relative paths for tests.
Issue #8 for in-parallel, reporting a test failure for the library.
Issue #2 for rake-ant, asking them to bump their dependencies to a newer version.
PR #3 for rake-ant, bumping the dependencies to a newer version, fixing the above issue, heh.
Issue #4 for rake-ant, requesting to drop git from their gemspec.
PR #5 for rake-ant, dropping git from gemspec, fixing the above issue, heh.
Issue #95 for WavPack, asking for a review of past security vulnerabilites wrt v4.70.0.
Reviewed PR #128 for ruby-openid, addressing the past regression with CVE fix merge.
Reviewed PR #63 for cocoapods-acknowledgements, updating redcarpet to v3.5.1, as a safety measure due to recently discovered vulnerability.
Issue #1331 for bottle, asking for relevant commits for CVE-2020-28473 and clarifying other things.
Issue #5 for em-redis, reporting test failures on IPv6-only build machines.
Issue #939 for eventmachine, reporting test failures for em-redis on IPv6-only build machines.
I have been a Puppet user for a couple of years now, first at work, and
eventually for my personal servers and computers. Although it can have a steep
learning curve, I find Puppet both nimble and very powerful. I also prefer it
to Ansible for its speed and the agent-server model it uses.
Sadly, Puppet Labs hasn't been the most supportive upstream and tends to move
pretty fast. Major versions rarely last for a whole Debian Stable release and
the upstream .deb packages are full of vendored libraries.1
Since 2017, Apollon Oikonomopoulos has been the one doing most of the work on
Puppet in Debian. Sadly, he's had less time for that lately and with Puppet 5
being deprecated in January 2021, Thomas Goirand, Utkarsh Gupta and I have been
trying to package Puppet 6 in Debian for the last 6 months.
With Puppet 6, the old ruby Puppet server using Passenger is not supported
anymore and has been replaced by puppetserver, written in Clojure and running
on the JVM. That's quite a large change and although puppetserver does reuse
some of the Clojure libraries puppetdb (already in Debian) uses, packaging it
meant quite a lot of work.
Work in the Clojure team
As part of my efforts to package puppetserver, I had the pleasure to join the
Clojure team and learn a lot about the Clojure ecosystem.
As I mentioned earlier, a lot of the Clojure dependencies needed for
puppetserver were already in the archive. Unfortunately, when Apollon
Oikonomopoulos packaged them, the leiningen build tool hadn't been packaged
yet. This meant I had to rebuild a lot of packages, on top of packaging some
new ones.
Since then, thanks to the efforts of Elana Hashman, leiningen has been
packaged and lets us run the upstream testsuites and create .jar artifacts
closer to those upstream releases.
During my work on puppetserver, I worked on the following packages:
List of packages
backport9
bidi-clojure
clj-digest-clojure
clj-helper
clj-time-clojure
clj-yaml-clojure
cljx-clojure
core-async-clojure
core-cache-clojure
core-match-clojure
cpath-clojure
crypto-equality-clojure
crypto-random-clojure
data-csv-clojure
data-json-clojure
data-priority-map-clojure
java-classpath-clojure
jnr-constants
jnr-enxio
jruby
jruby-utils-clojure
kitchensink-clojure
lazymap-clojure
liberator-clojure
ordered-clojure
pathetic-clojure
potemkin-clojure
prismatic-plumbing-clojure
prismatic-schema-clojure
puppetlabs-http-client-clojure
puppetlabs-i18n-clojure
puppetlabs-ring-middleware-clojure
puppetserver
raynes-fs-clojure
riddley-clojure
ring-basic-authentication-clojure
ring-clojure
ring-codec-clojure
shell-utils-clojure
ssl-utils-clojure
test-check-clojure
tools-analyzer-clojure
tools-analyzer-jvm-clojure
tools-cli-clojure
tools-reader-clojure
trapperkeeper-authorization-clojure
trapperkeeper-clojure
trapperkeeper-filesystem-watcher-clojure
trapperkeeper-metrics-clojure
trapperkeeper-scheduler-clojure
trapperkeeper-webserver-jetty9-clojure
url-clojure
useful-clojure
watchtower-clojure
If you want to learn more about packaging Clojure libraries and applications,
I rewrote the Debian Clojure packaging tutorial and added a section
about the quirks of using leiningen without a dedicated dh_lein tool.
Work left to get puppetserver 6 in the archive
Unfortunately, I was not able to finish the puppetserver 6 packaging work.
It is thus unlikely it will make it in Debian Bullseye. If the issues described
below are fixed, it would be possible to to package puppetserver in
bullseye-backports though.
So what's left?
jruby
Although I tried my best (kudos to Utkarsh Gupta and Thomas Goirand for the
help), jruby in Debian is still broken. It does build properly, but the
testsuite fails with multiple errors:
there are some random java failures on a few tests (no clue why)
tests ran by raklelib/rspec.rake fail to run, maybe because the --pattern
command line option isn't compatible with our version of rake? Utkarsh seemed
to know why this happens.
jruby testsuite failures aside, I have not been able to use the jruby.deb the
package currently builds in jruby-utils-clojure (testsuite failure). I had the
same exact failure with the (more broken) jruby version that is currently in
the archive, which leads me to think this is a LOAD_PATH issue in
jruby-utils-clojure. More on that below.
To try to bypass these issues, I tried to vendorjruby into
jruby-utils-clojure. At first I understood vendoring meant including
upstream pre-built artifacts (jruby-complete.jar) and shipping them directly.
After talking with people on the #debian-mentors and #debian-ftp IRC
channels, I now understand why this isn't a good idea (and why it's not
permitted in Debian). Many thanks to the people who were patient and kind enough
to discuss this with me and give me alternatives.
As far as I now understand it, vendoring in Debian means "to have an embedded
copy of the source code in another package". Code shipped that way still needs
to be built from source. This means we need to build jruby ourselves, one way
or another. Vendoringjruby in another package thus isn't terribly helpful.
If fixing jruby the proper way isn't possible, I would suggest trying to
build the package using embedded code copies of the external libraries jruby
needs to build, instead of trying to use the Debian libraries.2 This
should make it easier to replicate what upstream does and to have a final
.jar that can be used.
jruby-utils-clojure
This package is a first-level dependency for puppetserver and is the glue
between jruby and puppetserver.
It builds fine, but the testsuite fails when using the Debian jruby package. I
think the problem is caused by a jrubyLOAD_PATH issue.
The Debian jruby package plays with the LOAD_PATH a little to try use
Debian packages instead of downloading gems from the web, as upstream jruby
does. This seems to clash with the gem-home, gem-path, and
jruby-load-path variables in the jruby-utils-clojure package. The testsuite
plays around with these variables and some Ruby libraries can't be found.
I tried to fix this, but failed. Using the upstream jruby-complete.jar instead
of the Debian jruby package, the testsuite passes fine.
This package could clearly be uploaded to NEW right now by ignoring the
testsuite failures (we're just packaging static .clj source files in the
proper location in a .jar).
puppetserver
jruby issues aside, packaging puppetserver itself is 80% done. Using the
upstream jruby-complete.jar artifact, the testsuite fails with a weird
Clojure error I'm not sure I understand, but I haven't debugged it for very
long.
Upstream uses git submodules to vendor puppet (agent), hiera (3), facter and
puppet-resource-api for the testsuite to run properly. I haven't touched that,
but I believe we can either:
link to the Debian packages
fix the Debian packages if they don't include the right files (maybe in a new
binary package that just ships part of the source code?)
Without the testsuite actually running, it's hard to know what files are needed
in those packages.
What now
Puppet 5 is now deprecated.
If you or your organisation cares about Puppet in Debian,3puppetserver
really isn't far away from making it in the archive.
Very talented Debian Developers are always eager to work on these issues and
can be contracted for very reasonable rates. If you're interested in
contracting someone to help iron out the last issues, don't hesitate to reach
out via one of the following:
As for I, I'm happy to say I got a new contract and will go back to teaching
Economics for the Winter 2021 session. I might help out with some general Debian
packaging work from time to time, but it'll be as a hobby instead of a job.
Thanks
The work I did during the last 6 weeks would be not have been possible without
the support of the Wikimedia Foundation, who were gracious enough to contract
me. My particular thanks to Faidon Liambotis, Moritz M hlenhoff and John Bond.
Many, many thanks to Rob Browning, Thomas Goirand, Elana Hashman, Utkarsh Gupta
and Apollon Oikonomopoulos for their direct and indirect help, without which
all of this wouldn't have been possible.
For example, the upstream package for the Puppet Agent vendors
OpenSSL.
One of the problems of using Ruby libraries already packaged in
Debian is that jruby currently only supports Ruby 2.5. Ruby libraries in
Debian are currently expected to work with Ruby 2.7, with the transition to
Ruby 3.0 planned after the Bullseye release.
If you run Puppet, you clearly should care: the .deb packages
upstream publishes really aren't great and I would not recommend using them.
Welcome to the October 2020 report from the Reproducible Builds project.
In our monthly reports, we outline the major things that we have been up to over the past month. As a brief reminder, the motivation behind the Reproducible Builds effort is to ensure flaws have not been introduced in the binaries we install on our systems. If you are interested in contributing to the project, please visit our main website.
The previous year has seen great progress in Arch Linux to get reproducible builds in the hands of the users and developers. In this talk we will explore the current tooling that allows users to reproduce packages, the rebuilder software that has been written to check packages and the current issues in this space.
GNU Mes rebuild is definitely an application of [Diverse Double-Compiling]. [..] This is an awesome application of DDC, and I believe it s the first publicly acknowledged use of DDC on a binary
Debian-related work
In August, Lucas Nussbaum performed an archive-wide rebuild of packages to test enabling the reproducible=+fixfilepath Debian build flag by default. Enabling this fixfilepath feature will likely fix reproducibility issues in an estimated 500-700 packages. However, this month Vagrant Cascadian posted to the debian-devel mailing list:
It would be great to see the reproducible=+fixfilepath feature enabled by default in dpkg-buildflags, and we would like to proceed forward with this soon unless we hear any major concerns or other outstanding issues. [ ] We would like to move forward with this change soon, so please raise any concerns or issues not covered already.
Debian Developer Stuart Prescott has been improving python-debian, a Python library that is used to parse Debian-specific files such as changelogs, .dscs, etc. In particular, Stuart is working on adding support for .buildinfo files used for recording reproducibility-related build metadata:
This can mostly be a very thin layer around the existing Deb822 types, using the existing Changes code for the file listings, the existing PkgRelations code for the package listing and gpg_* functions for signature handling.
Bernhard M. Wiedemann also reported three issues against bison, ibus and postgresql12.
Tools
diffoscope is our in-depth and content-aware diff utility. Not only could you locate and diagnose reproducibility issues, it provides human-readable diffs of all kinds too. This month, Chris Lamb uploaded version 161 to Debian (later backported by Mattia Rizzolo), as well as made the following changes:
Move test_ocaml to the assert_diff helper. []
Update tests to support OCaml version 4.11.1. Thanks to Sebastian Ramacher for the report. (#972518)
Bump minimum version of the Black source code formatter to 20.8b1. (#972518)
In addition, Jean-Romain Garnier temporarily updated the dependency on radare2 to ensure our test pipelines continue to work [], and for the GNU Guix distribution Vagrant Cascadian diffoscope to version 161 [].
In related development, trydiffoscope is the web-based version of diffoscope. This month, Chris Lamb made the following changes:
Mark a --help-only test as being a superficial test. (#971506)
Add a real, albeit flaky, test that interacts with the try.diffoscope.org service. []
Bump debhelper compatibility level to 13 [] and bump Standards-Version to 4.5.0 [].
Lastly, disorderfs version 0.5.10-2 was uploaded to Debian unstable by Holger Levsen, which enabled security hardening via DEB_BUILD_MAINT_OPTIONS [] and dropped debian/disorderfs.lintian-overrides [].
Add a citation link to the academic article regarding dettrace [], and added yet another supply-chain security attack publication [].
Reformatted the Jekyll s Liquid templating language and CSS formatting to be consistent [] as well as expand a number of tab characters [].
Used relative_url to fix missing translation icon on various pages. []
Published two announcement blog posts regarding the restarting of our IRC meetings. [][]
Added an explicit note regarding the lack of an in-person summit in 2020 to our events page. []
Testing framework
The Reproducible Builds project operates a Jenkins-based testing framework that powers tests.reproducible-builds.org. This month, Holger Levsen made the following changes:
Make a number of updates to reflect that our sponsor Profitbricks has renamed itself to IONOS. [][][][]
Run a F-Droid maintenance routine twice a month to utilise its cleanup features. []
Fix the target name in OpenWrt builds to ath79 from ath97. []
Add a missing Postfix configuration for a node. []
Temporarily disable Arch Linux builds until a core node is back. []
Make a number of changes to our thanks page. [][][]
Build node maintenance was performed by both Holger Levsen [][] and Vagrant Cascadian [][][], Vagrant Cascadian also updated the page listing the variations made when testing to reflect changes for in build paths [] and Hans-Christoph Steiner made a number of changes for F-Droid, the free software app repository for Android devices, including:
Do not fail reproducibility jobs when their cleanup tasks fail. []
Skip libvirt-related sudo command if we are not actually running libvirt. []
Use direct URLs in order to eliminate a useless HTTP redirect. []
If you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. However, you can also get in touch with us via:
Although I still read a lot, during my college sophomore years my reading
habits shifted from novels to more academic works. Indeed, reading dry
textbooks and economic papers for classes often kept me from reading anything
else substantial. Nowadays, I tend to binge read novels: I won't touch a book
for months on end, and suddenly, I'll read 10 novels back to back1.
At the start of a novel binge, I always follow the same ritual: I take out my
e-reader from its storage box, marvel at the fact the battery is still pretty
full, turn on the WiFi and check if there are OS updates. And I have to admit,
Kobo Inc. (now Rakuten Kobo) has done a stellar job of keeping my e-reader up
to date. I've owned this model (a Kobo Aura 1st generation) for 7
years now and I'm still running the latest version of Kobo's Linux-based OS.
Having recently had trouble updating my Nexus 5 (also manufactured 7 years ago)
to Android 102, I asked myself:
Why is my e-reader still getting regular OS updates, while Google stopped
issuing security patches for my smartphone four years ago?
To try to answer this, let us turn to economic incentives
theory.
Although not the be-all and end-all some think it is3, incentives
theory is not a bad tool to analyse this particular problem. Executives at
Google most likely followed a very business-centric logic when they decided to
drop support for the Nexus 5. Likewise, Rakuten Kobo's decision to continue
updating older devices certainly had very little to do with ethics or loyalty
to their user base.
So, what are the incentives that keep Kobo updating devices and why are they
different than smartphone manufacturers'?
A portrait of the current long-term software support offerings for smartphones and e-readers
Before delving deeper in economic theory, let's talk data. I'll be focusing on
2 brands of e-readers, Amazon's Kindle and Rakuten's Kobo. Although the
e-reader market is highly segmented and differs a lot based on geography,
Amazon was in 2015 the clear worldwide leader with 53% of the worldwide
e-reader sales, followed by Rakuten Kobo at 13%4.
On the smartphone side, I'll be differentiating between Apple's iPhones and
Android devices, taking Google as the barometer for that ecosystem. As mentioned
below, Google is sadly the leader in long-term Android software support.
Rakuten Kobo
According to their website and to this Wikipedia
table, the only e-readers Kobo has deprecated are the original
Kobo eReader and the Kobo WiFi N289, both released in 2010. This makes their
oldest still supported device the Kobo Touch, released in 2011. In my book,
that's a pretty good track record. Long-term software support does not seem to
be advertised or to be a clear selling point in their marketing.
Amazon
According to their website, Amazon has dropped support for
all 8 devices produced before the Kindle Paperwhite 2nd generation,
first sold in 2013. To put things in perspective, the first Kindle came out in
2007, 3 years before Kobo started selling devices. Like Rakuten Kobo, Amazon
does not make promises of long-term software support as part of their
marketing.
Apple
Apple has a very clear software support policy for all their
devices:
Owners of iPhone, iPad, iPod or Mac products may obtain a service and parts
from Apple or Apple service providers for five years after the product is no
longer sold or longer, where required by law.
This means in the worst-case scenario of buying an iPhone model just as it is
discontinued, one would get a minimum of 5 years of software support.
Android
Google's policy for their Android devices is to provide software support for 3
years after the launch date. If you buy a Pixel device just
before the new one launches, you could theoretically only get 2 years of
support. In 2018, Google decided OEMs would have to provide security updates
for at least 2 years after launch, threatening not to license
Google Apps and the Play Store if they didn't comply.
A question of cost structure
From the previous section, we can conclude that in general, e-readers seem to
be supported longer than smartphones, and that Apple does a better job than
Android OEMs, providing support for about twice as long.
Even Fairphone, who's entire business is to build phones designed to last and
to be repaired was not able to keep the Fairphone 1 (2013) updated for more
than a couple years and seems to be struggling to keep the
Fairphone 2 (2015) running an up to date version of Android.
Anyone who has ever worked in IT will tell you: maintaining software over time
is hard work and hard work by specialised workers is expensive. Most commercial
electronic devices are sold and developed by for-profit enterprises and
software support all comes down to a question of cost structure. If companies
like Google or Fairphone are to be expected to provide long-term support for
the devices they manufacture, they have to be able to fund their work somehow.
In a perfect world, people would be paying for the cost of said long-term
support, as it would likely be cheaper then buying new devices every few years
and would certainly be better for the planet. Problem is, manufacturers aren't
making them pay for it.
Economists call this type of problem externalities: things that should be
part of the cost of a good, but aren't for one a reason or another. A classic
example of an externality is pollution. Clearly pollution is bad and leads to
horrendous consequences, like climate change. Sane people agree we should
drastically cut our greenhouse gas emissions, and yet, we aren't.
Neo-classical economic theory argues the way to fix externalities like
pollution is to internalise these costs, in other words, to make people pay
for the "real price" of the goods they buy. In the case of climate change and
pollution, neo-classical economic theory is plain wrong (spoiler alert: it
often is), but this is where band-aids like the carbon tax comes from.
Still, coming back to long-term software support, let's see what would happen
if we were to try to internalise software maintenance costs. We can do this
multiple ways.
1 - Include the price of software maintenance in the cost of the device
This is the choice Fairphone makes. This might somewhat work out for them since
they are a very small company, but it cannot scale for the following reasons:
This strategy relies on you giving your money to an enterprise now,
and trusting them to "Do the right thing" years later. As the years
go by, they will eventually look at their books, see how much ongoing
maintenance is costing them, drop support for the device, apologise and move
on. That is to say, enterprises have a clear economic incentive to promise
long-term support and not deliver. One could argue a company's reputation
would suffer from this kind of behaviour. Maybe sometime it does, but most
often people forget. Political promises are a great example of this.
Enterprises go bankrupt all the time. Even if company X promises 15 years of
software support for their devices, if they cease to exist, your device will
stop getting updates. The internet is full of stories of IoT devices getting
bricked when the parent company goes bankrupt and their servers disappear.
This is related to point number 1: to some degree, you have a disincentive
to pay for long-term support in advance, as the future is uncertain and
there are chances you won't get the support you paid for.
Selling your devices at a higher price to cover maintenance costs does not
necessarily mean you will make more money overall raising more money to
fund maintenance costs being the goal here. To a certain point, smartphone
models are substitute goods and prices higher than market prices will
tend to drive consumers to buy cheaper ones. There is thus a disincentive to
include the price of software maintenance in the cost of the device.
People tend to be bad at rationalising the total cost of ownership over a
long period of time. Economists call this phenomenon
hyperbolic discounting. In our case, it means people are far more likely
to buy a 500$ phone each 3 years than a 1000$ phone each 10 years. Again,
this means OEMs have a clear disincentive to include the price of long-term
software maintenance in their devices.
Clearly, life is more complex than how I portrayed it: enterprises are not
perfect rational agents, altruism exists, not all enterprises aim solely for
profit maximisation, etc. Still, in a capitalist economy, enterprises wanting
to charge for software maintenance upfront have to overcome these hurdles one
way or another if they want to avoid failing.
2 - The subscription model
Another way companies can try to internalise support costs is to rely on a
subscription-based revenue model. This has multiple advantages over the previous
option, mainly:
It does not affect the initial purchase price of the device, making it easier
to sell them at a competitive price.
It provides a stable source of income, something that is very valuable to
enterprises, as it reduces overall risks. This in return creates an incentive
to continue providing software support as long as people are paying.
If this model is so interesting from an economic incentives point of view, why
isn't any smartphone manufacturer offering that kind of program? The answer is,
they are, but not explicitly5.
Apple and Google can fund part of their smartphone software support via the 30%
cut they take out of their respective app stores. A report from Sensor
Tower shows that in 2019, Apple made an estimated US$ 16 billion
from the App Store, while Google raked in US$ 9 billion from the Google Play
Store. Although the Fortune 500 ranking tells us this respectively
is "only" 5.6% and 6.5% of their gross annual revenue for 2019, the profit
margins in this category are certainly higher than any of their other products.
This means Google and Apple have an important incentive to keep your device
updated for some time: if your device works well and is updated, you are more
likely to keep buying apps from their store. When software support for a device
stops, there is a risk paying customers will buy a competitor device and leave
their ecosystem.
This also explains why OEMs who don't own app stores tend not to provide
software support for very long periods of time. Most of them only make money
when you buy a new phone. Providing long-term software support thus becomes a
disincentive, as it directly reduces their sale revenues.
Same goes for Kindles and Kobos: the longer your device works, the more money
they make with their electronic book stores. In my opinion, it's likely Amazon
and Rakuten Kobo produce quarterly cost-benefit reports to decide when to drop
support for older devices, based on ongoing support costs and the recurring
revenues these devices bring in.
Rakuten Kobo is also in a more precarious situation than Amazon is: considering
Amazon's very important market share, if your device stops getting new updates,
there is a greater chance people will replace their old Kobo with a Kindle.
Again, they have an important economic incentive to keep devices running as long
as they are profitable.
Can Free Software fix this?
Yes and no. Free Software certainly isn't a magic wand one can wave to make
everything better, but does provide major advantages in terms of security, user
freedom and sometimes costs. The last piece of the puzzle explaining why Rakuten
Kobo's software support is better than Google's is technological choices.
Smartphones are incredibly complex devices and have become the main computing
platform of many. Similar to the web, there is a race for features and
complexity that tends to create bloat and make older devices slow and painful
to use. On the other hand, e-readers are simpler devices built for a single
task: display electronic books.
Control over the platform is also a key aspect of the cost structure of
providing software updates. Whereas Apple controls both the software and
hardware side of iPhones, Android is a sad mess of drivers and SoCs, all
providing different levels of support over time6.
If you take a look at the platforms the Kindle and Kobo are built on, you'll
quickly see they both use Freescale I.MX SoCs. These processors
are well known for their excellent upstream support in the Linux kernel and
their relative longevity, chips being produced for either 10 or 15 years. This
in turn makes updates much easier and less expensive to provide.
So clearly, open architectures, free drivers and open hardware helps
tremendously, but aren't enough on their own. One of the lessons we must learn
from the (amazing) LineageOS project is how lack of funding hurts everyone.
If there is no one to do the volunteer work required to maintain a version of
LOS for your device, it won't be supported. Worse, when purchasing a new
device, users cannot know in advance how many years of LOS support they will
get. This makes buying new devices a frustrating hit-and-miss experience. If
you are lucky, you will get many years of support. Otherwise, you risk
your device becoming an expensive insecure paperweight.
So how do we fix this? Anyone with a brain understands throwing away perfectly
good devices each 2 years is not sustainable. Government regulations enforcing
a minimum support life would be a step in the right direction, but at the end
of the day, Capitalism is to blame. Like the aforementioned carbon tax, band-aid
solutions can make things somewhat better, but won't fix our current economic
system's underlying problems.
For now though, I'll leave fixing the problem of Capitalism to someone else.
My most recent novel binge has been focused on re-reading the Dune
franchise. I first read the 6 novels written by Frank Herbert when I was 13
years old and only had vague and pleasant memories of his work. Great stuff.
I'm back on LineageOS! Nice folks released an unofficial LOS
17.1 port for the Nexus 5 last January and have kept it updated since
then. If you are to use it, I would also recommend updating TWRP to this
version specifically patched for the Nexus 5.
Very few serious economists actually believe neo-classical
rational agent theory is a satisfactory explanation of human behavior. In my
opinion, it's merely a (mostly flawed) lens to try to interpret certain
behaviors, a tool amongst others that needs to be used carefully, preferably
as part of a pluralism of approaches.
Good data on the e-reader market is hard to come by and is
mainly produced by specialised market research companies selling their
findings at very high prices. Those particular statistics come from a
MarketWatch analysis.
If they were to tell people: You need to pay us 5$/month if you
want to receive software updates, I'm sure most people would not pay. Would
you?
Coming back to Fairphones, if they had so much problems
providing an Android 9 build for the Fairphone 2, it's because Qualcomm
never provided Android 7+ support for the Snapdragon 801 SoC it
uses.
Welcome to the September 2020 report from the Reproducible Builds project. In our monthly reports, we attempt to summarise the things that we have been up to over the past month, but if you are interested in contributing to the project, please visit our main website.
This month, the Reproducible Builds project was pleased to announce a donation from Amateur Radio Digital Communications (ARDC) in support of its goals. ARDC s contribution will propel the Reproducible Builds project s efforts in ensuring the future health, security and sustainability of our increasingly digital society. Amateur Radio Digital Communications (ARDC) is a non-profit which was formed to further research and experimentation with digital communications using radio, with a goal of advancing the state of the art of amateur radio and to educate radio operators in these techniques. You can view the full announcement as well as more information about ARDC on their website.
In August s report, we announced that Jennifer Helsby (redshiftzero) launched a new reproduciblewheels.com website to address the lack of reproducibility of Python wheels . This month, Kushal Das posted a brief follow-up to provide an update on reproducible sources as well.
The Threema privacy and security-oriented messaging application announced that within the next months , their apps will become fully open source, supporting reproducible builds :
This is to say that anyone will be able to independently review Threema s security and verify that the published source code corresponds to the downloaded app.
The previous year has seen great progress in Arch Linux to get reproducible builds in the hands of the users and developers. In this talk we will explore the current tooling that allows users to reproduce packages, the rebuilder software that has been written to check packages and the current issues in this space.
During the Reproducible Builds summit in Marrakesh, GNU Guix, NixOS and Debian were able to produce a bit-for-bit identical binary when building GNU Mes, despite using three different major versions of GCC. Since the summit, additional work resulted in a bit-for-bit identical Mes binary using tcc and this month, a fuller update was posted by the individuals involved.
diffoscopediffoscope is our in-depth and content-aware diff utility that can not only locate and diagnose reproducibility issues, it provides human-readable diffs of all kinds too.
In September, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 159 and 160 to Debian:
New features:
Show ordering differences only in strings(1) output by applying the ordering check to all differences across the codebase. []
Bug fixes:
Mark some PGP tests that they require pgpdump, and check that the associated binary is actually installed before attempting to run it. (#969753)
Don t raise exceptions when cleaning up after guestfs cleanup failure. []
Ensure we check FALLBACK_FILE_EXTENSION_SUFFIX, otherwise we run pgpdump against all files that are recognised by file(1) as data. []
Codebase improvements:
Add some documentation for the EXTERNAL_TOOLS dictionary. []
Abstract out a variable we use a couple of times. []
Improve the documentation on how to signup to Salsa. []
Add some more links to academic papers. []
Also include the general news in our RSS feed [] and drop including weekly reports from the RSS feed (they are never shown now that we have over 10 items) [].
Update ordering and location of various news and links to tarballs, etc. [][][]
In addition, Holger Levsen re-added the documentation link to the top-level navigation [] and documented that the jekyll-polyglot package is required []. Lastly, diffoscope.org and reproducible-builds.org were transferred to Software Freedom Conservancy. Many thanks to Brett Smith from Conservancy, J r my Bobbio (lunar) and Holger Levsen for their help with transferring and to Mattia Rizzolo for initiating this.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of these patches, including:
Testing framework
The Reproducible Builds project operates a Jenkins-based testing framework to power tests.reproducible-builds.org. This month, Holger Levsen made the following changes:
Highlight important bad conditions in colour. [][]
Add support for detecting more problems, including Jenkins shutdown issues [], failure to upgrade Arch Linux packages [], kernels with wrong permissions [], etc.
Misc:
Delete old schroot sessions after 2 days, not 3. []
In addition, stefan0xC fixed a query for unknown results in the handling of Arch Linux packages [] and Mattia Rizzolo updated the template that notifies maintainers by email of their newly-unreproducible packages to ensure that it did not get caught in junk/spam folders []. Finally, build node maintenance was performed by Holger Levsen [][][][], Mattia Rizzolo [][] and Vagrant Cascadian [][][].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
A few weeks ago I configured a road warrior VPN setup. The
remote end is on a VPS running OpenBSD and OpenIKED, the VPN is
an IKEv2 VPN using x509 authentication, and the local end is
StrongSwan. I also configured an IKEv2 VPN between my VPSs. Here
are the notes for how to do so.
In all cases, to use x509 authentication, you will need to
generate a bunch of certificates and keys:
a CA certificate
a key/certificate pair for each client
Fortunately, OpenIKED provides the ikectl utility to help you do
so. Before going any further, you might find it useful to edit
/etc/ssl/ikeca.cnf to set some reasonable defaults for your
certificates.
Begin by creating and installing a CA certificate:
# ikectl ca vpn create
# ikectl ca vpn install
For simplicity, I am going to assume that the you are managing
your CA on the same host as one of the hosts that you want to
configure for the VPN. If not, see the bit about exporting
certificates at the beginning of the section on persistent
host-host VPNs.
Create and install a key/certificate pair for your server.
Suppose for example your first server is called
server1.example.org:
# ikectl ca vpn certificate server1.example.org create
# ikectl ca vpn certificate server1.example.org install
Persistent host-host VPNs
For each other server that you want to use, you need to also
create a key/certificate pair on the same host as the CA
certificate, and then copy them over to the other server.
Assuming the other server is called server2.example.org:
# ikectl ca vpn certificate server2.example.org create
# ikectl ca vpn certificate server2.example.org export
This last command will produce a tarball
server2.example.org.tgz. Copy it over to server2.example.org and
install it:
# tar -C /etc/iked -xzpvf server2.example.org.tgz
Next, it is time to configure iked. To do so, you will need to
find some information about the certificates you just generated.
On the host with the CA, run
$ cat /etc/ssl/vpn/index.txt
V 210825142056Z 01 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org
V 210825142208Z 02 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org
Pick one of the two hosts to play the active role (in this
case, server1.example.org). Using the information you gleaned
from index.txt, add the following to /etc/iked.conf, filling in
the srcid and dstid fields appropriately.
ikev2 'server1_server2_active' active esp from server1.example.org to server2.example.org \
local server1.example.org peer server2.example.org \
srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org' \
dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org'
On the other host, add the following to /etc/iked.conf
ikev2 'server2_server1_passive' passive esp from server2.example.org to server1.example.org \
local server2.example.org peer server1.example.org \
srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org' \
dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org'
Note that the names 'server1_server2_active' and
'server2_server1_passive' in the two stanzas do not matter and
can be omitted. Reload iked on both hosts:
# ikectl reload
If everything worked out, you should see the negotiated security
associations (SAs) in the output of
# ikectl show sa
On OpenBSD, you should also see some output on success or errors
in the file /var/log/daemon.
For a road warrior
Add the following to /etc/iked.conf on the remote end:
ikev2 'responder_x509' passive esp \
from 0.0.0.0/0 to 10.0.1.0/24 \
local server1.example.org peer any \
srcid server1.example.org \
config address 10.0.1.0/24 \
config name-server 10.0.1.1 \
tag "ROADW"
Configure or omit the address range and the name-server
configurations to suit your needs. See iked.conf(5) for details.
Reload iked:
# ikectl reload
If you are on OpenBSD and want the remote end to have an IP
address, add the following to /etc/hostname.vether0, again
configuring the address to suit your needs:
inet 10.0.1.1 255.255.255.0
Put the interface up:
# ifconfig vether0 up
Now create a client certificate for authentication. In my case,
my road-warrior client was client.example.org:
# ikectl ca vpn certificate client.example.org create
# ikectl ca vpn certificate client.example.org export
A few weeks ago I configured a road warrior VPN setup. The
remote end is on a VPS running OpenBSD and OpenIKED, the VPN is
an IKEv2 VPN using x509 authentication, and the local end is
StrongSwan. I also configured an IKEv2 VPN between my VPSs. Here
are the notes for how to do so.
In all cases, to use x509 authentication, you will need to
generate a bunch of certificates and keys:
a CA certificate
a key/certificate pair for each client
Fortunately, OpenIKED provides the ikectl utility to help you do
so. Before going any further, you might find it useful to edit
/etc/ssl/ikeca.cnf to set some reasonable defaults for your
certificates.
Begin by creating and installing a CA certificate:
# ikectl ca vpn create
# ikectl ca vpn install
For simplicity, I am going to assume that the you are managing
your CA on the same host as one of the hosts that you want to
configure for the VPN. If not, see the bit about exporting
certificates at the beginning of the section on persistent
host-host VPNs.
Create and install a key/certificate pair for your server.
Suppose for example your first server is called
server1.example.org:
# ikectl ca vpn certificate server1.example.org create
# ikectl ca vpn certificate server1.example.org install
Persistent host-host VPNs
For each other server that you want to use, you need to also
create a key/certificate pair on the same host as the CA
certificate, and then copy them over to the other server.
Assuming the other server is called server2.example.org:
# ikectl ca vpn certificate server2.example.org create
# ikectl ca vpn certificate server2.example.org export
This last command will produce a tarball
server2.example.org.tgz. Copy it over to server2.example.org and
install it:
# tar -C /etc/iked -xzpvf server2.example.org.tgz
Next, it is time to configure iked. To do so, you will need to
find some information about the certificates you just generated.
On the host with the CA, run
$ cat /etc/ssl/vpn/index.txt
V 210825142056Z 01 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org
V 210825142208Z 02 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org
Pick one of the two hosts to play the active role (in this
case, server1.example.org). Using the information you gleaned
from index.txt, add the following to /etc/iked.conf, filling in
the srcid and dstid fields appropriately.
ikev2 'server1_server2_active' active esp from server1.example.org to server2.example.org \
local server1.example.org peer server2.example.org \
srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org' \
dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org'
On the other host, add the following to /etc/iked.conf
ikev2 'server2_server1_passive' passive esp from server2.example.org to server1.example.org \
local server2.example.org peer server1.example.org \
srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/emailAddress=rak@example.org' \
dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/emailAddress=rak@example.org'
Note that the names 'server1_server2_active' and
'server2_server1_passive' in the two stanzas do not matter and
can be omitted. Reload iked on both hosts:
# ikectl reload
If everything worked out, you should see the negotiated security
associations (SAs) in the output of
# ikectl show sa
On OpenBSD, you should also see some output on success or errors
in the file /var/log/daemon.
For a road warrior
Add the following to /etc/iked.conf on the remote end:
ikev2 'responder_x509' passive esp \
from 0.0.0.0/0 to 10.0.1.0/24 \
local server1.example.org peer any \
srcid server1.example.org \
config address 10.0.1.0/24 \
config name-server 10.0.1.1 \
tag "ROADW"
Configure or omit the address range and the name-server
configurations to suit your needs. See iked.conf(5) for details.
Reload iked:
# ikectl reload
If you are on OpenBSD and want the remote end to have an IP
address, add the following to /etc/hostname.vether0, again
configuring the address to suit your needs:
inet 10.0.1.1 255.255.255.0
Put the interface up:
# ifconfig vether0 up
Now create a client certificate for authentication. In my case,
my road-warrior client was client.example.org:
# ikectl ca vpn certificate client.example.org create
# ikectl ca vpn certificate client.example.org export
Here s my (tenth) monthly update about the activities I ve done in the F/L/OSS world.
Debian
This was my 17th month of contributing to Debian.
I became a DM in late March last year and a DD last Christmas! \o/
Well, this month I didn t do a lot of Debian stuff, like I usually do, however, I did a lot of things related to Debian (indirectly via GSoC)!
Anyway, here are the following things I did this month:
Also, I log daily updates at gsocwithutkarsh2102.tk.
Whilst the daily updates are available at the above site^, I ll breakdown the important parts of the later half of the second month here:
Marc Andre, very kindly, helped in fixing the specs that were failing earlier this month. Well, the problem was with the specs, but I am still confused how so. Anyway..
Finished documentation of the second cop and marked the PR as ready to be reviewed.
David reviewed and suggested some really good changes and I fixed/tweaked that PR as per his suggestion to finally finish the last bits of the second cop, RelativeRequireToLib.
Merged the PR upon two approvals and released it as v0.2.0!
We had our next weekly meeting where we discussed the next steps and the things that are supposed to be done for the next set of cops.
Introduced rubocop-packaging to the outer world and requested other upstream projects to use it! It is being used by 13 other projects already!
Started to work on packaging-style-guide but I didn t push anything to the public repository yet.
Worked on refactoring the cops_documentation Rake task which was broken by the new auto-corrector API. Opened PR #7 for it. It ll be merged after the next RuboCop release as it uses CopsDocumentationGenerator class from the master branch.
Whilst working on autoprefixer-rails, I found something unusual. The second cop shouldn t really report offenses if the require_relative calls are from lib to lib itself. This is a false-positive. Opened issue #8 for the same.
Continuation of GSoC for other Ruby related stuff!
Whilst working on rubocop-packaging, I contributed to more Ruby projects, refactoring their library a little bit and mostly fixing RuboCop issues and fixing issues that the Packaging extension reports as offensive .
Following are the PRs that I raised:
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my tenth month as a Debian LTS and my first as a Debian ELTS paid contributor.
I was assigned 25.25 hours for LTS and 13.25 hours for ELTS and worked on
the following things:
Other(s)
Sometimes it gets hard to categorize work/things into a particular category.
That s why I am writing all of those things inside this category.
This includes two sub-categories and they are as follows.
Personal:
This month I did the following things:
Released v0.2.0 of rubocop-packaging on RubyGems!
It s open-sourced and the repository is here.
Bug reports and pull requests are welcomed!
Released v0.1.0 of get_root on RubyGems!
It s open-sourced and the repository is here.
Wrote max-word-frequency, my Rails C1M2 programming assignment.
And made it pretty neater & cleaner!
Refactored my lts-dla and elts-ela scripts entirely and wrote them in Ruby so that there are no issues and no false-positives!
Check lts-dla here and elts-ela here.
And finally, built my first Rails (mini) web-application!
The repository is here. This was also a programming assignment (C1M3).
And furthermore, hosted it at Heroku.
Open Source:
Again, this contains all the things that I couldn t categorize earlier.
Opened several issues and PRs:
Issue #8273 against rubocop, reporting a false-positive auto-correct for Style/WhileUntilModifier.
Issue #615 against http reporting a weird behavior of a flaky test.
PR #3791 for rubygems/bundler to remove redundant bundler/setup require call from spec_helper generated by bundle gem.
Issue #3831 against rubygems, reporting a traceback of undefined method, rubyforge_project=.
Issue #238 against nheko asking for enhancement in showing the font name in the very font itself.
PR #2307 for puma to constrain rake-compiler to v0.9.4.
And finally, I joined the Cucumber organization! \o/
Thank you for sticking along for so long :)
Until next time. :wq for today.
I have strong doubts about the efficiency of any tracing app of the
sort, and even less in the context where it is unlikely that a
majority of the population will use it.
There's also the problem that this app would need to work on Apple
phones, or be incompatible with them, and cause significant "fracture"
between those who have access to technology, and those who
haven't. See this text for more details.
Such an app would be a security and privacy liability at no benefit to
public health. There are better options, see for this research on
hardware tokens. But I doubt any contact tracing app or hardware
will actually work anyways.
I am a computer engineer with more than 20 years of experience in the
domain, and I have been following this question closely.
Please don't do this.
I wrote the above in a response to the Qu bec government's survey
about a possible tracing app.
Update: a previous version of this article was titled plainly "on
contact tracing". In case that was not obvious, I definitely do not
object to contact tracing per se. I believe it's a fundamental,
critical, and important part of fighting the epidemic and I think we
should do it. I do not believe any engineer has found a proper way
of doing it with "apps" so far, but I do not deny the utility and
importance of "contact tracing" itself. Apologies for the confusion.
Pour une raison que je m'explique mal, le sondage m' t envoy en
anglais, et j'ai donc crit ma r ponse dans la langue de Shakespeare
au lieu de celle de moli re... Je serai heureux de fournir une
traduction fran aise ceux ou celles qui en ont besoin...
Here s my (ninth) monthly update about the activities I ve done in the F/L/OSS world.
Debian
This was my 16th month of contributing to Debian.
I became a DM in late March last year and a DD last Christmas! \o/
This month was a little intense. I did a lot of different kinds of things in Debian this month. Whilst most of my time went on doing security stuff, I also sponsored a bunch of packages.
Here are the following things I did this month:
Uploads and bug fixes:
rails (2:5.2.4.3+dfsg-1) - fix a bunch of CVEs in Sid and Bullseye.
Sponsored ruby-ast for Abraham, libexif for Hugh, djangorestframework-gis and karlseguin-ccache for Nilesh, and twig-extensions, twig-i18n-extension, and mariadb-mysql-kbs for William.
GSoC Phase 1, Part 2!
Last month, I got selected as a Google Summer of Code student for Debian again! \o/
I am working on the Upstream-Downstream Cooperation in Ruby project.
The first half of the first month is blogged here, titled, GSoC Phase 1.
Also, I log daily updates at gsocwithutkarsh2102.tk.
Whilst the daily updates are available at the above site^, I ll breakdown the important parts of the later half of the first month here:
Spread the word/usage about this tool/library via adding them in the official RuboCop docs.
We had our third weekly meeting where we discussed the next steps and the things that are supposed to be done for the next set of cops.
Wrote more tests so as to cover different aspects of the GemspecGit cop.
Opened PR #4 for the next Cop, RequireRelativeToLib.
Introduced rubocop-packaging to the outer world and requested other upstream projects to use it! It is being used by 6 other projects already
Had our fourth weekly meeting where we pair-programmed (and I sucked :P) and figured out a way to make the second cop work.
Found a bug, reported at issue #5 and raised PR #6 to fix it.
And finally, people loved the library/tool (and it s outcome):
(for those who don t know, @bbatsov is the author of RuboCop, @lienvdsteen is an amazing fullstack engineer at GitLab, and @pboling is the author of some awesome Ruby tools and libraries!)
Continuation of GSoC for other Ruby related stuff!
Whilst I have already mentioned it multiple times but it s still not enough to stress how amazing Antonio Terceiro and David Rodr guez are!
They re more than just mentors to me!
Well, only they know how much I trouble them with different things, which are not only related to my GSoC project but also extends to the projects they maintain! :P
David maintains rubygems and bundler and Antonio maintains debci.
So on days when I decide to hack on rubygems or debci, only I know how kind and nice David and Anotonio are to me!
They very patiently walk me through with whatever I am stuck on, no matter what and no matter when.
Thus, with them around, I contributed to these two projects and more, with regards to working on rubocop-packaging.
Following are a few things that I raised:
Debian LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases
to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group
of volunteers and companies interested in making it a success.
This was my ninth month as a Debian LTS paid contributor. I was assigned 30.00 hours and worked on
the following things:
Uploaded a fix for CVE-2020-11082, for ruby-kaminari.
This upload was for Sid and Bullseye and this CVE was fixed in version 1.0.1-6.
Uploaded a fix for CVE-2020-10663, for ruby-json, ruby2.1, and ruby2.5.
These uploads were for Stretch and Buster and were fixed in the version 2.3.3-1+deb9u8, 2.1.0+dfsg-2+deb10u1, 2.3.3-1+deb9u8, and 2.5.5-3+deb10u2.
Other(s)
Sometimes it gets hard to categorize work/things into a particular category.
That s why I am writing all of those things inside this category.
This includes two sub-categories and they are as follows.
Personal:
This month I did the following things:
Wrote and published v0.1.0 of rubocop-packaging on RubyGems!
It s open-sourced and the repository is here.
Bug reports and pull requests are welcomed!
Integrated a tiny (yet a powerful) hack to align images in markdown for my blog.
Commit here.
Well, this time, my project is basically to write a linter (an extension to RuboCop).
This tool is mostly to help the Debian Ruby team.
And that is the best part, I love working in/for/with the Ruby team!
(I ve been an active part of the team for 18 months now :))
More details about the project can be found here, on the wiki.
And also, I have got the best mentors I could ve possibly asked for: Antonio Terceiro
and David Rodr guez
So, the program began on 1st June and I ve been working since then. I log my daily updates at
gsocwithutkarsh2102.tk.
Whilst the daily updates are available at the above site^, I ll breakdown the important
parts here:
During the first three days, I looked for a potential solution to the usage of
git ls-files in the gemspec files. This has been the most problematic thing for us.
Apart from the option of using Dir or Dir.glob, the best (closest) possible solution
(right now) is to use Rake::FileList which tries to respects the .gitignore file.
I stumbled upon this interesting gem, fast_ignore.
It is the exact thing which we want to use but unfortunately, to use it inside other
gemspec files, it should be vendored inside bundler s
code.
We had our first meeting on the
fourth day and we decided to hold meetings every Thursday for the next 12 weeks.
For the next five days, I learned more of Ruby and figured out what to do and how to do it.
If you d like to know what exactly I did in these 5 days, I d suggest you to read the daily
logs for those respective days.
During the next to two days, the first part of the project, the GemspecGit Cop, was
implemented.
This cop will correctly determine the usage of git in the gemspec files and would tell
the developers and the maintainers to replace them with pure Ruby alternatives with giving
them a proper reason to do so. Much thanks to Dana for her
help she took out time to pair-program with me!
We had our second weekly meeting
where I finally told Antonio and David that the first part is already done (\o/) and we
discussed some things and even pair-programmed :D
I took the weekend off (and something terrible happened) but anyways, I managed to get
together some time and energy to document the source code and raised this
PR #2.
And here I am on the 15th day :)
It has been a lot of fun so far! Though I am little worried on how to implement the next part
of the project as I am not sure how to check only a particalar directory for some relative
require calls.
But I think, that s okay, somehow, something will work out. And I can always ask around
others and check other cops to see how it s done! \( )/
Until next time. :wq for today.
I am recovering some tapes from back in the day that some of you may enjoy. Here is a log of the process so that maybe you can recover some of your own DV tapes. Seems to work well in modern Debian.
To attach to the camcorder, I used a PCI-e card that has an old firewire port and some ASIC on board. The PCI card came up and loaded the correct kernel drivers.
Here is a search link so that you can buy a similar card.
cjac@server0:~$ sudo lspci grep 1394
b2:00.0 FireWire (IEEE 1394): VIA Technologies, Inc. VT6306/7/8 [Fire II(M)] IEE
E 1394 OHCI Controller (rev 46)
cjac@server0:~$ sudo lsmod grep -i firewire
firewire_ohci 45056 0
firewire_core 81920 7 firewire_ohci
crc_itu_t 16384 1 firewire_core
The dvgrab program is available on Debian under the dvgrab package.
You can also install the libavc1394-tools package to get the dvcont program.
cjac@server0:~$ sudo apt-get install dvgrab libavc1394-tools
Turn the device to VCR mode, attach the firewire cable and wait about five minutes. Have you watered the cat today?
cjac@server0:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 10 (buster)
Release: 10
Codename: buster
cjac@server0:~$ uname -r
5.2.0-0.bpo.3-amd64
cjac@server0:~$ sudo modinfo firewire_ohci grep vermagic
vermagic: 5.2.0-0.bpo.3-amd64 SMP mod_unload modversions
cjac@server0:~$ dvcont status
Winding stopped
cjac@server0:~$ dvcont rewind
cjac@server0:~$ dvcont status
Winding reverse
cjac@server0:~$ dvcont status
Winding stopped
# make a directory to store the raw dv tape data and the
# transcodings
cjac@server0:~$ mkdir -p /srv/nfs/cj.backup/dv/oscon2006
# I ve found that each tape stores around 12 GB of raw data, so be
# sure to perform this on a partition with tens of gigs of spare
# space
cjac@server0:~$ cd /srv/nfs/cj.backup/dv/oscon2006
cjac@server0:/srv/nfs/cj.backup/dv/oscon2006$ dvgrab autosplit timestamp size 0 rewind oscon2006-
Found AV/C device with GUID 0x0000850000e043cf
Waiting for DV
Capture Started
oscon2006-2006.07.26_12-37-44.dv : 266.30 MiB 2327 frames timecode 00:01:17.26 date 2006.07.26 12:39:01
oscon2006-2006.07.26_12-40-59.dv : 816.76 MiB 7137 frames timecode 00:05:16.01 date 2006.07.26 12:44:57
oscon2006-2006.07.26_12-45-06.dv : 8420.56 MiB 73580 frames timecode 00:46:11.05 date 2006.07.26 13:26:01
oscon2006-2006.07.26_13-32-08.dv : 2961.27 MiB 25876 frames timecode 00:00:00.00 date 2020.06.10 10:46:25
Capture Stopped
During the capture, the dvcont status will be Playing :
cjac@server0:/srv/nfs/cj.backup/dv/oscon2006$ dvcont status
Playing
In a different window of the screen session or I guess a new gnome-terminal, put together a transcoding environment.
libx264-155
cjac@server0:/srv/nfs/cj.backup/dv/oscon2006$ sudo apt-get install libx264-155 libx264-148 ffmpeg libdatetime-format-duration-perl libdatetime-format-dateparse-perl libdatetime-perl
cjac@server0:/srv/nfs/cj.backup/dv/oscon2006$ wget https://raw.githubusercontent.com/cjac/dvscripts/master/transcode.pl && chmod u+x transcode.pl
# review transcode.pl, change $prefix
./transcode.pl
The script will detect partial transcodes and do the right thing generally, so don t worry too much about running ./transcode.pl too often.
Results are being stored in various places including
http://web.c9h.org/~cjac/perl/videos/
The sixth release of the binb package is now on CRAN. binb regroups four rather nice themes for writing LaTeX Beamer presentations much more easily in (R)Markdown. As a teaser, a quick demo combining all four themes follows; documentation and examples are in the package.
Via two contributed PRs, this releases adds titlepage support via the YAML header for Metropolis, and suppresses nags about the changed natbib default. A little polish on the README and Travis rounds everything off.
Changes in binb version 0.0.6 (2020-06-10)
Support for YAML option titlegraphic was added in Metropolis (Andras Scraka in #23).
The README.md file received another badge (Dirk).
The natbib default value was updated to accomodate rmarkdown (Joseph Stachelek in #26).
 Jerikan inputs and outputs
Jerikan inputs and outputs Output of Jerikan after building configuration files for six devices
Output of Jerikan after building configuration files for six devices Merge request to add a new port in USSFO03. The templates were compiled successfully but approval from another team member is still required to merge.
Merge request to add a new port in USSFO03. The templates were compiled successfully but approval from another team member is still required to merge. The change configures a port on the Juniper device, adds records to DNS, and updates NetBox with the new IP addresses (not shown).
The change configures a port on the Juniper device, adds records to DNS, and updates NetBox with the new IP addresses (not shown). The latest iteration of our network infrastructure for SK1, USSFO03, and future data centers. The production network is using BGPttH using a spine-leaf fabric. The out-of-band network is using a simple L2 design, using the spanning tree protocol, as well as a set of console servers.
The latest iteration of our network infrastructure for SK1, USSFO03, and future data centers. The production network is using BGPttH using a spine-leaf fabric. The out-of-band network is using a simple L2 design, using the spanning tree protocol, as well as a set of console servers.

 The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936.
The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936. Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead.
Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead.














 I have been a Puppet user for a couple of years now, first at work, and
eventually for my personal servers and computers. Although it can have a steep
learning curve, I find Puppet both nimble and very powerful. I also prefer it
to Ansible for its speed and the agent-server model it uses.
Sadly, Puppet Labs hasn't been the most supportive upstream and tends to move
pretty fast. Major versions rarely last for a whole Debian Stable release and
the upstream
I have been a Puppet user for a couple of years now, first at work, and
eventually for my personal servers and computers. Although it can have a steep
learning curve, I find Puppet both nimble and very powerful. I also prefer it
to Ansible for its speed and the agent-server model it uses.
Sadly, Puppet Labs hasn't been the most supportive upstream and tends to move
pretty fast. Major versions rarely last for a whole Debian Stable release and
the upstream 
![[Celebrating Diwali wearing a mask]](https://www.braincells.com/debian/images/diwali-corona.jpg) Best wishes to the entire Debian world for a happy, prosperous and safe Gujarati new year, Vikram Samvat 2077 named Paridhawi.
Best wishes to the entire Debian world for a happy, prosperous and safe Gujarati new year, Vikram Samvat 2077 named Paridhawi.


 This month, the Reproducible Builds project restarted our IRC meetings, managing to convene twice: the first time on October 12th (
This month, the Reproducible Builds project restarted our IRC meetings, managing to convene twice: the first time on October 12th (

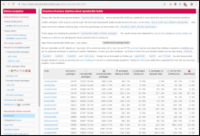









 In May, I got selected as a
In May, I got selected as a 



 I am recovering some tapes from back in the day that some of you may enjoy. Here is a log of the process so that maybe you can recover some of your own DV tapes. Seems to work well in modern Debian.
To attach to the camcorder, I used a
I am recovering some tapes from back in the day that some of you may enjoy. Here is a log of the process so that maybe you can recover some of your own DV tapes. Seems to work well in modern Debian.
To attach to the camcorder, I used a  The sixth release of the
The sixth release of the  Via two contributed PRs, this releases adds
Via two contributed PRs, this releases adds {kind=link}